A Nemzeti Névterek megvalósításának néhány kérdése
A Nemzeti Névtér létrehozásának és működtetésének igazi értelme abban van, hogy a névterek közös archívumi használata révén átjárhatóvá tegyük a kulturális gyűjteményi adatbázisokat. Csak azáltal tudjuk megmutatni a magyar kultúra teljességét, kulturális értékeink összességét a maguk egybefüggő egymáshoz kapcsolódásukban, teljes összefüggésrendszerükben, ha a közös névterek működtetése révén összekapcsoljuk a kulturális gyűjteményeinket. Amíg a kulturális adatokat a közgyűjteményi logika szerint intézményes elkülönültségben tároljuk, addig szükségszerűen csak szigetszerű hozzáférést nyújthatunk az érdeklődők számára. A cél az, hogy a látogatók, ahelyett, hogy archívumról archívumra vándorolniuk kelljen ahhoz, hogy az őket érdeklő adatokat összegyűjthessék, egyetlen integrált rendszerként láthassák és használhassák a magyar kulturális adatbázisok összességét. Ehhez arra van szükség, hogy a lokális archívumi adatrendszerek a közös névtér-használatok révén átjárhatókká váljanak. Megjegyzés: A kulturális értékeink iránt érdeklődő látogató nem arra kíváncsi, hogy valamely archívumban mit tudnak egyenként mutatni az őt érdeklő személyekkel, testületekkel vagy városokkal kapcsolatos könyvekről, filmekről, zenemávekről, képekről, műtárgyakról. hanem mindezeket egyszerre szeretné megkapni. A látogatót József Attila, Bartók Béla vagy Neumann János könyvei és képei és filmjei, nem pedig könyvei vagy képei vagy filmjei érdeklik. Korábban ez nem volt lehetséges, de a hálózati összekapcsoltság révén ma már – elméletileg – ez megvalósítható. Ehhez kellenek a Névterek, hiszen ezek elemei, a személynevek, testületi nevek, földrajzi nevek stb. teszik lehetővé az archívumok közti tényleges tartalmi kapcsolatok kiépítését.
A Nemzeti Névtér projekt célcsoportjai
A Nemzeti Névtér projekt stratégiai célcsoportja, az elkészült rendszer elsőrendű haszonélvezője az érdeklődő nagyközönség. A Nemzeti Névtér felépítése által tehetjük igazán hozzáférhetővé kulturális értékeinket a digitális nemzeti kulturális örökség iránt érdeklődő látogatók (laikusok, kutatók, szakemberek) számára. A stratégiai cél elérésére, a nagyközönség igényeinek kiszolgálására azonban akkor van nagyobb esélyünk, ha a Nemzeti Névtér felépítéséig és biztonságos működtetéséig a Névteret adminisztráló archívumok szempontjaira figyelünk elsősorban. Taktikai megfontolások miatt tehát kétlépcsős fejlesztési ütemezést érdemes követnünk, mely szerint a fejlesztés első ütemében az archívumok szempontjai és elvárásait veszzük figyelembe, és csak a második körben építjük ki azokat a funkcionalitásokat, szolgáltatásokat, amelyek a közönség érdeklődésére is számot tarthatnak.
Megjegyzés: i) Ez a dokumentum a Nemzeti Névtér felépítését végző archívumi szakemberek számára szól, a Nemzeti Névtér felépítéséhez és működtetéséhez szükséges teendőket próbálja meg összegyűjteni. ii) A fent jelzett – önmérsékletet kívánó – ütemezésre nagy szükség van, mert a népszerűnek ígérkező szolgáltatások első körbe emelése vélhetőleg agyon nyomná a projekt egészét.
Az adathitelesség kérdése
A Nemzeti Névtér eszméjéből értelemszerűen fakad az az elképzelés, hogy a Nemzeti Névtérnek fel kell vállalnia egyfajta adathitelesítő szerepet is. Az elképzelés szerint akár érdeklődő laikus, akár adatgazdai szervezet keresné fel a Nemzeti Névteret, az a megkeresésekre hitelesített, ellenőrzött, egyértelműsített adatokat szolgáltatna. Ezt a stratégia célt vállalnunk kell, de ezt az elvárást nem szabad indulási feltételként szabnunk. Idővel kialakulhat az a minőség, amely alapján már mondani lehet, hogy a közös névtér adathiteles szolgáltatóként is funkcionál, de egyrészt ezen állapot eléréséhez több idő kell, másrészt tudni kell és tudomásul kell venni azt, hogy a Nemzeti Névtérnek mindig lesznek olyan területei, adatszegmensei, rekordjai, ahol nem leszünk képesek teljesen hiteles adatokat garantálni.
Ezen a ponton felmerül a kérdés, hogy akkor hogyan működhet a Nemzeti Névtér az adathitelesség szempontjából tekintve. Ha nem tudjuk garantálni az adott névhordozóhoz, névhez tartozó adatok hitelességét, egyértelműségét, akkor mit csinálunk, ha egymásnak ellentmondó, vagy nem eléggé megbízhatónak tartott adatok érkeznek be a különböző adatgazdáktól a Központi Névtérbe.
Példa: Különböző archívumok irányából három – eltérő – születési adat érkezik be egy személyre vonatkozóan.
A versengő rekordok/mezők elvének elfogadása
Rendszerszerűen arra a működésmódra kell berendezkedni, hogy a különböző adatforrásokból érkezhetnek egymásnak ellentmondó adatok, amelyeket – bizonyos, még kidolgozandó valószínűségek és heurisztikák mellett – meghagyunk, és ezáltal egymásnak némiképp ellentmondó, tehát versengő adatrekordok, adatmezők létét engedjük meg. Adat szinten ez – nem kívánatos – inkonzisztenciát jelent, de egyrészt első körben úgysem tudjuk megakadályozni a jelenség létezését, tehát vagy „kitiltjuk” (de akkor nem lesz semmilyen adatunk) vagy megtűrjük, másrészt fel lehet építeni egy olyan mechanizmust, amely humán és gépi erőket igénybe véve folyamatosan próbálja csökkenteni az inkonzisztens rekordok számát és arányát.
Példa: Tisztázandó, hogy az új mezők mellett új rekordokat kell-e felvenni akkor, ha egy személyhez több születési adat érkezik be, vagy ilyenkor csak egy rekordot hagyunk meg, és versengő mezőket engedünk meg.
Megjegyzés: i) Tisztázni kell még azt, hogy mit jelent a versengő rekordok/mezők elve a névhordozók és nevek rekordjait illetően. ii) Mivel az adatok forrásait mindig ismerjük, ezért mind az adatmegjelenítés, mind a keresés számára definiálni lehet egy rögzített forráshierarchiát, amit a keresési relevanciák megállapításakor, és bármilyen hitelességi kérdés eldöntésekor figyelembe lehet venni. iii) Az adatkonzisztencia megteremtésének, az adathitelesség biztosításának módjaira ki kell dolgozni egy közös szabályrendszert, ami a lokális archívumokban és a központi névtér szerkesztőségben folyó munkákat szabályozza. iv) Az adathitelesség kérdésének – humán – szabályozását természetesen meg kell támogatni egy szofisztikált jogosultsági, értesítési és ellenőrzési – informatikai – rendszerrel is.
Megbízhatósági index bevezetése
Ki lehetne alakítani egy olyan megbízhatósági indexet (heurisztikát és módszertant), amely valahogyan automatikusan mérné és jelezné, hogy egyes adatelemek, adatrekordok milyen megbízhatósági szinten vannak, és nyilván valamilyen érték felett (vagy alatt) a rendszer figyelmeztetést küldhetne megfelelő helyre, hogy valahol a rendszerben beavatkozásra váró inkonzisztencia lépett fel.
Közösségi őrző szemek az adatkonszolidálásban
Az inkonziztens adatok „javítása” a Nemzeti Névtér adminisztrátorainak feladata. Egyelőre nem látszik mód és szándék arra, hogy nyitni lehetne e téren a közösségi adatbázis-kezelés irányába. Ez azonban nem jelenti azt, hogy ne lehetne bevonni a „laikus” érdeklődőket ebbe a munkába. Nem közösségi adatbázis-építésre kell felkészülni, hanem közösségi adatellenőrzésre. Nem szerkesztési, csak ellenőrzési lehetőséget kell felkínálni a laikus érdeklődők számára, azt viszont nagyon is biztosítani kell. Egy az egyben alkalmazhatjuk magunkra a Linus’ Law mondását: "given enough eyeballs, all bugs are shallow", vagyis minél több szem ellenőrzi a névterek adatait, annál több hibát találhatunk meg és javíthatunk ki. A közösség erejét a hibák feltárásában, jelzésében és a helyes adatok esetleges begyűjtésében kell látnunk, ami után a hibák, hiányok tényleges javítása, a szerkesztési művelet megmaradhat a Névtéren belül, az adminisztrátorok jogosultságában. Természetesen ehhez olyan alkalmazást és felületet kell kifejleszteni, amelyen keresztül a laikusok egyszerűen végezhetik ezt a fajta figyelő szolgálatukat.
Névtér-adatbázisok frissítése: „bent épül, kint frissül”
Az egyik kritikusabb praktikus tervezési feladat annak eldöntése, hogy milyen módon lehet frissíteni a névterek adatállományait. Ezen a ponton fontos fogalmilag szétválasztani a központi Nemzeti Névtér és az egyes archívumi névterek frissítési problémáit, de úgy, hogy eközben egységes gyakorlati választ tudjunk majd adni a fenti kérdésre. A lehetséges alternatívák kifejtése előtt rögzítenünk kell azt a tényt, hogy mind a központi Nemzeti Névtér, mind a lokális archívumi névterek alapvetően a lokális archívumok munkatársainak adatkezelő munkája révén épülhetnek. Ha valamilyen adatmanipulációs feladat adódik (módosítani kell egy névhordozó- és/vagy egy névrekordot vagy épp egy újat kell felvenni), akkor alapvetően a lokális archivátoroknak kell ezt a munkát elvégeznie. A továbbiakban koncentráljunk a kritikus feladatra, egy új névrekord felvételére. Ez a feladat megköveteli, hogy mind a saját, mind a központi névtérbe bekerüljön egy új név- és névhordozórekord (a továbbiakban erre – ha az nem zavaró – egységesen névrekordként hivatkozunk). A nagy kérdés itt az, hogy milyen elv és megoldás szerint lehet új rekordot beilleszteni a rendszerbe. Két elv közül érdemes választanunk: vagy a „kint épül, bent frissül” vagy a „bent épül, kint frissül” módszert követhetjük. Az első elv szerint a lokális névtér-adatbázisba kerül be először az új névrekord, majd ezután valamilyen szüretelési vagy szinkronizálási algoritmus révén átkerül a központi névtérbe is. A második elv értelmében a lokális archivátornak elsőként a központi névtér-adatbázisba kell felvennie az új rekordot, majd onnan azonnal át kell származtatnia a központi névtér-azonosítót a lokális adatbázisba a második lépésben felvett új lokális névrekord megfelelő mezőjébe.
Mindkét megoldásnak vannak gyenge pontjai, mégis az utóbbi elv látszik megvalósíthatónak, mert csak ezáltal lehet fenntartani a központi névtér konzisztenciáját. Az első megoldás esetén ugyanis a központba bekerülő új névadatokat egy újabb humán ellenőrzésen keresztül lehetne csak felvenni központi névrekordként. Erre pedig sosem lesz kapacitás.
Megjegyzés: A lokális névtérhasználat esetében az archívumi metaadatrendszerekben a névhordozókkal kapcsolatos mezőkbe úgy veszik fel a nevek (névhordozók) azonosítóit, hogy a választható nevekből listát generálnak, ahonnan a megfelelő nevet kiválasztva a hozzá tartozó mesterséges azonosító is bekerül a helyére. Ha a beillesztendő név (és névhordozó) nem szerepel még a lokális névtér alapján generált listában, akkor „ideiglenesen” ki kell lépni a metaadatrendszerből, és új névrekordot kell felvenni a névtér erre a célra kialakított felületén. A következő lépésben már az új névrekordot is ki lehet választani a metaadatrendszeren belül.
A közösségi névtérhasználat esetén az első lépés feladatai semmiben sem különböznek az eddig leírtaktól, mert ha a lokális névtérben megtalálható a keresett név (és névhordozó), akkor azzal már ki lehet építeni a kapcsolatokat a metaadatrendszeren belül. Az új mozzanat (és feladat) az új névrekordok felvétele esetén jelentkezik. Ekkor annyi a változás, hogy nem a lokális, hanem a központi névtérbe kell átlépni, és ott kell az új rekordot felvenni. Természetesen gépi automatizmusokon keresztül azonnal át kell származtatni az új rekordokat a lokális névterekbe is, hogy a központban felvett új neveket (névhordozókat) már a lokális névtérből lehessen a metaadatrendszerbe beilleszteni.
Névtérgazdai szerepek
Bár középtávon nem látszik feltétlenül szükségesnek, az indulás nehézségeit feltételezve az első időszakra érdemes névtérgazdai szerepeket definiálnunk, amiken valamely névtérrel kapcsolatos munkálatok felügyeleti, szabályozási felelősségét értjük. Ezek a kötelezettségek primus inter pares alapon emelnék csak ki a névtérgazdát a többi archívumi szereplő közül, amennyiban ugyanis beindulnának a központi névterek, úgy a dolgok logikájából adódóan önfenntartóvá válhatna a munkamenet, ami már nem kívánna erős felügyelő szerepeket és szereplőket. Az indulás előre nem látható, de nagyon is várható problémái azonban szükségessé teszik az ilyenfajta szerepek definiálását és – időleges – érvényesítését. Bár meg kell engednünk, hogy a közös névterek építésébe közgyűjtemények mellett más intézmények, más szereplők (magánarchívumok, akár magánszemélyek) is beszállhassanak, a névtérgazda szerepeket érdemes közgyűjteményi szereplőkhöz rendelnünk.
Sovány szemantika
A névtér-projekt sikerének egyik záloga lehet az az elhatározás, hogy a legminimálisabb programot akarjuk csak megvalósítani az első körben. A minimálprogram szerint pedig a központi névtér egyetlen feladata a nevek és névhordozók egyértelmű azonosítása és központi Névtérben kiosztott azonosítók átszármaztatása a lokális névterekbe. Ha valóban csak ezt a feladatot rendeljük a névtér-projekt első szakaszához, akkor ezzel együtt kijelenthetjük azt is, hogy nincs szükség archívumi ontológiák, metaadatrendszerek (MARC, RDA, AACR2, bármi) beemelésére a projektbe. Nem szabad bármelyik gazdag szemantikával megterhelni a projektet, mert úgysem használnánk ki a névtérépítés során. A kezdetekben elégséges, sőt, kívánatos a sovány, szegény szemantika. Első körben csak abban kell megegyeznünk, hogy i) miként kell modellezni az egyes névhordozótípusokat és a hozzájuk tartozó neveket, ii) milyen adatelemekkel tudják, akarják az egyes archívumok ellátni a névjegyeket ahhoz, hogy saját gyakorlatuk szerint el tudják végezni a nevek, névhordozók azonosítását, iii) a közös névhordozó- és névmodell adatelemeit hogyan kell rávetíteni egyfelől az egyes archívumok saját metarendszereire, másrészt a legfontosabb adatcsereszabványokra.
Nemzeti Névtér Központi Szerkesztőség
Arra a kérdésre, vajon kell-e központi szerkesztőség, egyértelműen ’igen’ választ kell adnunk. Valamifajta központi tisztító, konszolidáló munkakörre biztos szükség van, hiszen a közös működtetés következményeként arra kell számítanunk, hogy folyamatosan keletkeznek a lokális szereplők által „vitatott” és/vagy inkonzisztens állapotban hagyott adatértékek, melyek „meg- és feloldására” központi felelősséget kell definiálni, és a feladathoz megfelelő kapacitást kell biztosítani. Arra kérdésre, hogy egy ilyen szerkesztőségnek mekkorának kell lennie, milyen nagyságrendű feladatai lehetnek, nehezebb válaszolni. Egyrészt ezt az archívumi névtér-adatbázisok első körös összefésülése után lehet megbízhatóbban megbecsülni, másrészt a létszám és a bevállalható feladatkör függ az e célra biztosított állami pénzügyi erőforrásoktól is.
Adatbázis-konszolidáció, -tisztítás
A közös névtérépítés nem megy emberi szakértelem nélkül. A gépi intelligencia, a gépi heurisztikák több területen is segítséget nyújthatnak, de az adattisztítási munka legnehezebb részében nem lehet a gépekre számítani. Emberi beavatkozásra van szükség i) a lokális archívumi névtér-adatbázisok önmagában vett fel- és továbbépítésében, ii) a projekt indulásakor a lokális névterek integrálásával kialakítandó közös névterek adattisztításában, valamint iii) az indulás után a folyamatosan termelődő többértelműségek, adathiányok és adathibák javításában, pótlásában.
Retrospektív konszolidáció
A közös adatbázisok kialakítása, az adattisztítási munkák elvégzése jelenti talán a legnagyobb feladatot, ami irdatlan indulási/bekerülési költséget jelent, de ennek megvalósítása nélkül nincs értelme a projektről beszélni. Ehhez állami források biztosítására van szükség.
Folyamatos konszolidáció
Ha feltételezzük, hogy felállt az egységes közös névtér-adatbázis, akkor is folyamatos keletkeznek, újratermelődnek többértelműségek, hibák, hiányok, amelyek javítása, pótlása folyamatos konszolidációs munkát követel meg. Döntően e feladat végzésére kellene a központi szerkesztőséget felállítani.
Adattisztító közmunkások
Esély mutatkozik arra, hogy az adattisztítási munkákra igénybe lehessen venni a közgyűjteményi szférából elbocsátott szakembereket állami visszafoglalkoztatási támogatásokon keresztül.
Névtér, névjegy, névadatlap
Egy archívumon belül a névtérhasználat azzal jár, hogy az archívum metaadatrendszerében szereplő névmezőkbe nem a konkrét névértékeket, hanem az önálló névtáblákba írt nevek azonosítóit mint idegenkulcsokat írják be. Ehhez a neveket (és névhordozókat) önálló entitásként kell kezelni, amelyekre vonatkozóan normalizálni kell az archívumi metaadatrendszer adatbázisát. Ez a megoldás egyben azt is lehetővé teszi, hogy a névhordozókra vontakozóan ki lehessen gyűjteni az összes olyan kapcsolatot, amelyben a névhordozók „érintve vannak” az archívumi gyűjtemény adatrendszerében.
Példa: Egy könyvtáron belül a könyvek bibliográfiai adatainak leírásakor beírhatunk személyneveket a könyv szerzőjeként, szerkesztőjeként, fordítójaként stb. Ha személynévteret használunk, akkor a könyvek és személyek közti kapcsolatok inverzei mentén fel tudjuk építeni a személyek és könyvek közti fordított relációkat is, vagyis ki tudjuk listázni adott személy összes könyves kapcsolatát: melyik könyvnek volt a szerzője, szerkesztője, fordítója stb. Egy filmtárban az egyes filmekre vonatkozó filmográfiákból az inverzkapcsolatok mentén fel lehet építeni a személyek filmes kapcsolódásait: adott személy melyik filmekkel, milyen módon hozható kapcsolatba.
Amint elkülönült entitásként kezelik a neveket (és névhordozókat), lehetőség van arra, hogy a névhordozóhoz (névhez) további adatokat lehessen hozzárendelni. Ez megteremti annak lehetőségét, hogy a névhordozók adatmodelljének szemantikáját tetszőleges módon bővíthessük.
Példa: A személynévtér esetében a személyekhez mint személynévhordozó entitásokhoz már hozzárendelhetjük a személyek születési és halálozási adatait, foglalkozási szerepeit, családi kapcsolatait stb.
Adott archívumban valamely névhordozóra vonatkozóan két irányból lehet információt szerezni: amíg névtér (névhordozó-tér) felől a névhordozó saját adatait, addig az archívumi meatadatrendszer inverzkapcsolatai alapján a gyűjteményi elemek és a névhordozók közti kapcsolatok adatait lehet megtudni. Az adott archívum adatrendszerének egyik fontos szolgáltatása lehet a névhordozókhoz tartozó (a teljes archívumi adatrendszerből „kibányászható”) összes adat megjelenítése: ezt nevezhetjük névadatlapnak. Ennek kezelését (a névadatlap adatainak kitöltését) adott archívumi adatrendszer önálló funkciójaként, feladataként kell minősítenünk. Egy névadatlap olykor rendkívül gazdag, máskor meg szegényes adattartalommal rendelkezhet (például egy „öreg filmesnek” sok filmje, kapcsolata lehet, míg egy kezdőnek kevés).
A névtérépítés és -használat egyik kritikus pontja, komoly nehézsége az azonos névvel rendelkező, egymástól eltérő névhordozók megkülönböztetése. A névszinonimitás hiányában nagyon egyszerű lenne névtereket építeni, használni. Az archívumban az azonos nevű névhordozók szétválasztáshoz a névadatlapokhoz rendelt (vagy rendelhető) adatokat lehet használni (semmi többet). Első körben feltételezhetjük, hogy a névadatlapon található információ mindig (de legalábbis az esetek döntő többségében) elégséges lehet a szinonimitások „szétbontására”, valamint a nevek egyértelmű azonosítására. Azt viszont biztosan állíthatjuk, hogy a névtérhaszálat során, amikor neveket kell megtalálnunk, megkülönböztetnünk a névtérben, akkor nem vagy csak nagyon nehézkesen lehetne a névadatlapok által nyújtott összes adattal dolgozni: a névadatlapok „túl sok” adata kontraproduktívvá válna ebben az esetben. Ezért kell definiálni a névjegyet, amit egy csökkentett adattartalmú névadatlapként foghatunk fel, azzal a céllal, funkcionalitással, hogy a lehető legkevesebbb, de még éppen elégséges adatot tartalmazva a leghatékonyabban tudja segíteni a névkeresési és névazonosítási munkákat. Minden archívum kialakíthatja azt a sablont, azt a szűrőt, amely a számára legjobb névjegyeket állítja elő a saját archívumi névadatlapjaiból. Ebből az is következik, hogy ugyanarra a névhordozóra vonatkozóan két archívum másfajta névjegyet állít elő (mert más adatok állnak rendelkezésére, illetve az „átfedő” adattartalmakban esetleg más részeket tartanak fontosnak a saját praxisukon belül). A közös nemzeti névtér működtetésekor természetesen érdemes (szükséges) a lokális archívumi névjegyekből egy közös névjegyet létrehozni.
Előfordulhat, hogy a névjegyek használatakor mégsem lehet egyértelmű döntésre jutni valamiért. Ilyen esetekre készülve biztosítani kell azt a lehetőséget, hogy a névjegyekről azonnal el lehessen jutni a névadatlapokra, hogy az azokon található összes információhoz hozzá lehessen férni. Ennek a megvalósítási módját alaposabban meg kell tervezni, mert egyelőre nem tűnik triviálisnak, hogy hogyan lehet (érdemes) a közös névtérhasználat során egy névjegyről megmutatni és elugratni a felhasználót az összes létező adatlapra.
Megjegyzés: i) A könyvtári gyakorlatban a névjegy itt használt fogalmának a ’tételfej’, míg a névadatlap fogalmának a ’névcikk’ vagy ’szócikk’ kifejezések felelnek meg. ii) Mivel az itt javasolt közös névjegykezelésre még nincs nemzetközi gyakorlat, ezért a résztvevő feleknek kell ezt az együttműködést támogató új módszert közösen megtervezni, megvitatni és elfogadni.
A közös alkalmazás-réteg fejlesztése
A névtérkezelés nehéz, odafigyelést és fegyelmezettséget kívánó munkáját csak akkor remélhetjük a résztvevőktől, ha komoly informatikai támogatást tudunk nyújtani a rendszert építő archivátorok számára. A résztvevő archívumok számára a közös névtérkezelés egyik kölcsönös haszna lehet az az előny, hogy a közös névtér-adatbázist „működtető” névtér-alkalmazás is közös lesz, és ezt a közös alkalmazást a lehető legnagyobb intelligenciával tudjuk ellátni. A program specifikációja, majd implementálása az egész projekt egyik kulcskérdése (és a siker egyik záloga) lehet. Ennek során egyrészt közösen használt adatbázisokat és alkalmazásokat kell felépíteni, kifejleszteni, másrészt a közös erőforrások használatát lehetővé tevő, kiegészítő lokális fejlesztéseket és adatbázisokat kell ki- és felépíteni, harmadrészt köztes rétegeket is meg kell tervezni, majd fel kell építeni, ami az egyes rendszerek – interfészeken, protokollokon keresztüli – kommunikációját is lehetővé teszi. Ezt a fejlesztést állami forrásaiból kell megfinaszírozni, mivel a résztvevő archívumoknak nem lesz erre fordítható erőforrásuk.
Újrahasznosítható gépi heurisztikák
A közös névtér-adatbázisok kialakítása során számíthatunk gépi támogatásra a névszinonimitás, a többértelműség-feloldás kezelésében. Ezeket a verifikációs algoritmusokat, adattisztító heurisztikákat, többértelműséget csökkentő megoldásokat úgy kell megtervezni, majd implementálni, hogy önálló modulként részét alkossák a közös alkalmazásrétegnek, amit bármikor újrahasznosítani lehet új névtér-adatbázisok integrálásakor vagy más névtípusok névtereinek építésekor.
Együttműködési feltételek
A közös névtérépítési munkát a lokális archívumokban, illetve a központi névtér szerkesztőségben dolgozó szakemberek végzik. A hatékonyság és egyértelműség érdekében pontosan meg kell tervezni köztük zajló munkafolyamatokat, amire támaszkodva részletes munkaszervezési szabályzatban kell rögzíteni az együttműködésben résztvevők jogosultságait és kötelezettségeit.
Lokális informatikai beágyazások
A központi, közös alkalmazásréteg kifejlesztése mellett arra is szükség van, hogy minden résztvevő archívum számára elkészüljenek azok az informatikai ráfejlesztések, kiegészítések, amelyek a közös névtérhasználat miatti új funkcionalitások biztosításához kellenek. Olyan új funkciók jelennek meg (a közös névtér-adatbázis elérése, új rekordok bevitele, az idegenkulcsok kezelése, a névjegyek, névadatlapok szolgáltatása stb.), amelyeket valahogyan be kell ágyazni a már működő archívumi adatrendszerekbe, lokális alkalmazásokba.
Ezeket a fejlesztéseket megintcsak a névtér-projektnek kell finanszíroznia, hiszen ez is új feladatnak és új költségnek számít.
A névtérre épülő szolgáltatások
Amint elkészül egy névtér, utána azonnal bele lehet kezdeni olyan alkalmazásfejlesztésekbe, amelyek eredményeként a nagyközönség szemében is könnyen népszerűvé váló szolgáltatásokat remélhetünk. Az archívumi névterek adatlapjaira beszervezhető adatokat egy közös és publikus felületre lehet irányítani, ami már komoly értéket jelenthet az érdeklődő látogatók számára, tehát a névtér-projekt második lépésében már relatíve kicsi munkával népszerű szolgáltatások indítására is adódik lehetőség.
Példa: A közös személynévtér kiépítése után a közös névtér alapadataira, valamint az integrált archívumi adatlapok adataira támaszkodva nem igazán komoly fejlesztési igényű munkával létre lehetne hozni egy olyan személynévtárat, amely műfajilag leginkább egy életrajzi lexikonhoz hasonlítana, és amely iránt mind az intézmények, mind az érdeklődő közönség felől komoly igényt feltételezhetünk.
Igazodás a szabványokhoz
Egyelőre csak az elvet érdemes rögzíteni, miszerint mindvégig tudatosan meg kell felelnünk annak az elvárásnak, hogy messzemenően igazodjunk mind a hazai, mind a nemzetköz szabványokhoz.
A Nemzeti Névtér réteges architektúrája
A Nemzeti Névtér felépítését – többszörösen is – réteges és osztott módon kell elképzelnünk és megvalósítanunk. A Nemzeti Névtér lényege az együttműködésben (kollaborációban) van, de ez nem alapulhat erős központosításon, hanem sokkal inkább a közös szabványokon, részben közös, részben saját erőforrások használatán és közös működési renden tud csak mindez megvalósulni. Ezt a rétegzettséget és osztottságot mutatja az alábbi ábra.
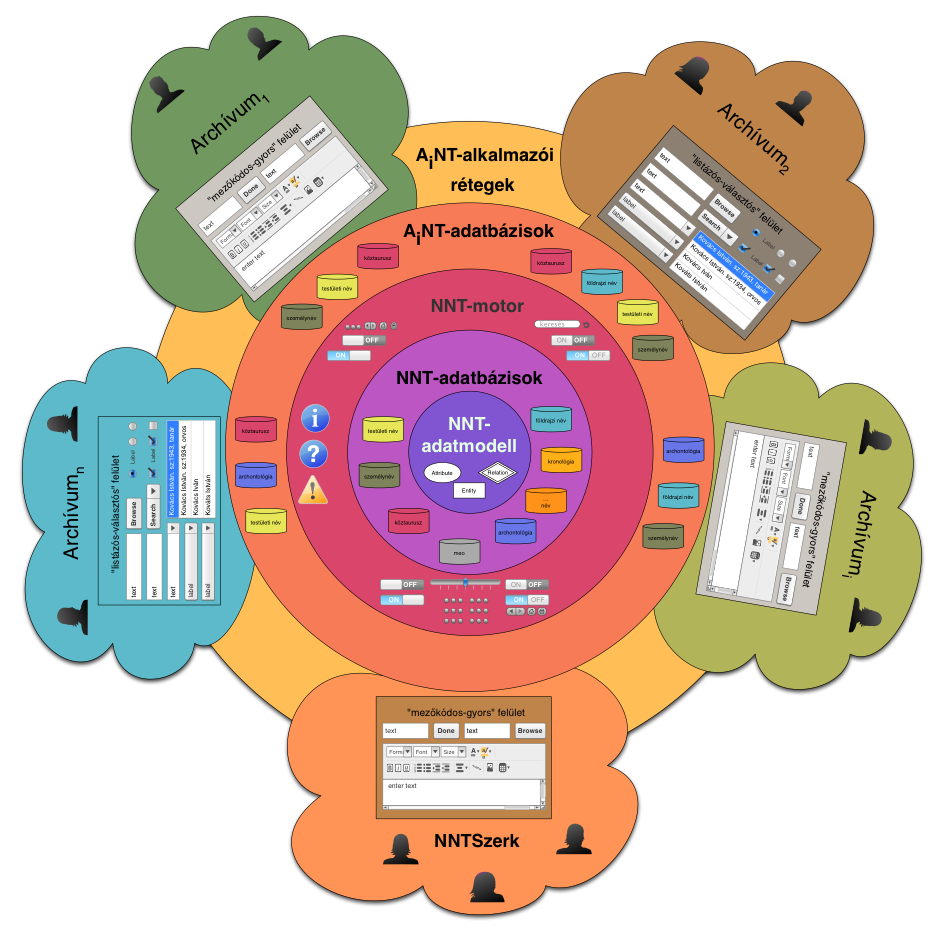
A névtér-rendszerrel szembeni alapvető elvárások, együttműködési elvek
- A névtér-adatbázisok legyenek nyílt tartalmak vagyis legyenek szabadon felhasználhatóak.
- A névtér-adatbázisokhoz bármikor integrálni lehessen külső adatforrások adatbázisait.
- Meg kell teremteni a nemzetközi névterekhez való kapcsolódás, a folyamatos adatszinkronizálás lehetőségét.
- Ki kell alakítani, ill. adaptálni kell azokat a protokollokat, adatcsere szabványokat, kommunikációs formátumokat, amelyeken révén megvalósítható az adatok kétirányú cseréje a központi névtér és bármely más archívum névtere között, illetve amelyeken keresztül további alkalmazásokat (lexikonokat, képanyagokat, bibliográfiai jegyzeteket stb.) lehet a névtér-rendszerre építeni (nem a szűken vett névtér-szolgáltatás részeként, hanem önálló modulként: „névtár-funkció”).
- A névtér elemeinek gyors és egyértelmű azonosítása, azonosíthatósága érdekében biztosítani kell az intelligens névjegy-kezelő funkcionalitást. Olyan – adatzoomolási elven működő – névadatlapokat kell létrehozni, amelyek segítségével minden archívum- és tárolószakmai elvárást ki lehet elégíteni a nevek, névhordozók azonosítása érdekében.
Megjegyzés: i) Ennek megtervezéséhez minden érintett fél szempontjait figyelembe kell venni. ii) Az adatzoomolás azt jelenti, hogy a nevekhez rendelhető összes adatot nem egyszerre, hanem több lépésben, egyre mélyülő részletességgel kell megjeleníteni, hogy az elején ne terheljük agyon a „túl sok adattal” az egyszerűen kezelhető eseteket.
- Arra kell törekedni, hogy a névtér-rendszer alapállapotában csak a legszükségesebb adat- és funkciórétegeket mutassa a használói számára, hogy minél gyorsabban és egyszerűbben lehessen a névtér-rendszer alapfunkcióját használni, vagyis a nevek gyors behasonlítására, azonosítására és/vagy kiválasztására használni, és csak akkor váljék láthatóvá minden – a névtérben egyébként elméletileg mindig elérhető – információ, ha a nehezebben azonosítható és/vagy kiválasztható nevek esetében erre szükség van.
- Biztosítani kell a különböző névterek közti átjárhatóságot, amikor a nevek, névhordozók azonosításához szükséges másfajta névlistákat kell megjeleníteni.
Megjegyzés: Példa erre testületek esetében közgyűjtemények, közintézmények, egyesületek, alapítványok vagy épp személyek listájának felmutatása.
- Ahol lehetséges és értelmes, biztosítani kell a nevek időbeliségének kezelését.
Megjegyzés: A földrajzi nevek esetében mindenképpen értelmes a nevek, közigazgatási státusok időbeli változásait megmutatni.
- Biztosítani kell, hogy az azonos névhordozóhoz tartozó összes névváltozatot – a megfelelő típusjelzésekkel együtt – látni, kezelni lehessen.
Megjegyzés: Egy névtér alapentitása nem a név, hanem a névhordozó, a neveken keresztül mindig valamilyen névhordozót keresünk (nem ’Kovács István’ nevet, hanem azt a személyt keressük, akinek Kovács István a neve – esetleg más, egyéb név mellett.)
- Biztosítani kell, hogy az egységesített besorolási minősítést a különböző szakmák, archívumok igényeihez igazodóan többszörözni lehessen.
- Meg kell tervezni és ki kell alakítani az olyan jogosultsági (és az ehhez igazodó felelősségi) rendszert, amelyben gyors, de ellenőrzött jóváhagyási mechanizmusok működhetnek. Ehhez intelligens, automatikus megfeleltetési ajánlatokra képes algoritmusokat kell fejleszteni, és megfelelő felületeket kell biztosítani a gépi és laikus felhasználói ajánlatok szakmai (humán) jóváhagyásához.
- Biztosítani kell olyan felületeket, amelyek a szakmai egyeztetések, szakmai viták lefolytatására alkalmasak.
- Biztosítani kell, hogy intelligens, profilírozható keresési funkciók álljanak rendelkezésre a névtér-rendszer minden pontján és felületén.
- Biztosítani kell, hogy a névtér-rendszer minden pontján lehessen szakterületi igények szerinti szűrést alkalmazni, hogy a közös rendszert használó partnerek csak a saját munkájukhoz szükséges adat- és funkciórétegeket láthassák, ha ezt igénylik maguknak.
- A névtér alkalmazások szakmai hátterének biztosítására állandó Nemzeti Névtér Bizottságot kell felállítani, amelynek tagjai közül kerülhetnek ki később az egyes névterek szakmai felelősei.
- A nemzeti névtér-rendszer megtervezésekor az alábbi névtípusokkal érdemes foglalkozni:
- tulajdonnevek
- földrajzi nevek
- személynevek
- családnevek
- testületi nevek
- rendezvénynevek
- műcímek
- köznevek
- általános fogalmak nevei
- szakkifejezések (anyagok, tárgyak, folyamatok, tulajdonságok, elvont fogalmak nevei)
- élőlények, szervek
- dokumentum-, információ- és adattípusok
- nyelvek
- népek
- foglalkozások
- tudományok, szakterületek
- kronologikus (időt jelentő) kifejezések
- eseménynevek
- Érdemes a földrajzi névtér adatbázis felépítésével kezdeni a munkát, mert ez a névtér mindenki számára közel egyenlő mértékben lehet fontos, és a névtér-adatbázis mérete, elemeinek számossága felülről lényegében korlátos, ami megvalósítható nagyságrendű feladatot valószínűsít.
- Ha a finanszírozási feltételek előteremthetőek, akkor érdemes elkezdeni a nagyközönség számára nagyobb vonzerőt ígérő személynévtér kialakítását, valamint az erre építhető további szolgáltatások (névtár funkciók) fejlesztését.
- A névterek adatainak bővítését, javítását, változtatását a közreműködő archívumok, adattárak szakemberei végzik.
- Szükség van valamilyen Névtér Szerkesztőségre, amelynek feladata a vitás, megoldandó kérdések rendezése, a nemzeti szintű integráció és a nemzetközi szintű kapcsolatrendszerek kialakítása, fenntartása.
- Olyan integrált névtér-rendszert szükséges megtervezni és kifejleszteni, amely egységes informatikai alapokra épül.
- A központi névtér-alkalmazás legyen platformfüggetlen, lehetőség szerint nyílt forráskódú és szabad szoftveres alapokra támaszkodjék minden lényeges komponens.
- A központi névtér-alkalmazás kifejlesztésén és üzemeltetésén túl meg kell finanszírozni azokat a kiegészítő fejlesztéseket is, amelyek a lokális rendszerek központi névtérbe csatlakozásához szükségesek.
- A névtér alkalmazások informatikai kiépítésének és üzemeltetésének szakmai és finanszírozási felelőse az állam.
Megjegyzés: i) A nemzetközi névtér-kezdeményezések közül megemlíthetjük a VIAF-ot. ii) A nemzetközi névterekhez való kapcsolat kiépítése és fenntartása jelentős emberi és gépi erőforrások igénybevételével oldható meg, amit a nemzeti névtér program keretében kell megfinanszírozni.
Megjegyzés: i) Adatcsere-formátumként megemlíthetjük pl. a MARC, EAC szabványokat. ii) Valamely névtár funkció kifejlesztése nem szükséges a nemzeti névtér kiépítéséhez és fenntartásához, de a névterekben tárolt adatok értelemszerű és a nagyközönség számára vonzó továbbhasznosításaként értelmes minél előbb ilyen funkciókat megvalósítani. iii) A névtár funkciók kifejlesztését csak a névterek működése esetén lehet elkezdeni. iV) A névtár funkciók és a nemzeti névtér finanszírozását el kell választani egymástól.
Megjegyzés: i) A nemzeti névtér tényleges működését csak akkor remélhetjük, ha a rendszer nem rak lényegesen nagyobb terhet a névtérkezelést végző lokális szakemberek vállára a közös munka során. Ezért nem szabad túlterhelni olyan adatokkal a lokális végpontokban dolgozó archivátorok kezelőfelületeit, amelyeket ők ott fölöslegesnek éreznek. ii) Mindemellett természetesen biztosítani kell azt is, hogy a rendszer bármely pontján mindenkor el lehessen érni a máshol tárolt adatokat (mégha több lépésben is).
Megjegyzés: i) Könnyen előfordulhat, hogy a különböző archívumi szakmák (könyvtárosok, levéltárosok, filmtárosok stb.) vagy akár az azonos szakmába sorolható különböző archívumok (OSZK és Kolozsvári Egyetemi Könyvtár) olykor eltérő besorolási minősítéseket ad meg bizonyos névhordozók esetében. A nemzeti névtér működtetéséhez nem szükséges egyesíteni a lokálisan egységesített besorolási minősítéseket. ii) Azt viszont természetesen biztosítani kell, hogy minden lokális résztvevő saját egységesített besorolási rendszerét láthassa viszont a központi névtéren keresztüli használat esetén is. Erre informatikailag (megfelelő nézetek kialakításával) módot kell teremteni.
Megjegyzés: A nemzeti névtér tényleges működését a lokális archívumok szakembereinek közös munkája biztosíthatja. A siker záloga az együttműködés láthatatlan feltételeinek megteremtése.
Megjegyzés: Minden közreműködő archívum adatfeldolgozó tevékenységét saját informatikai rendszer szolgálja ki, amelybe „egyenként” kell beilleszteni (belefejleszteni) azt a modilt, amely révén lehetővé válik a kooperáció.